
Vers un web sans internet
Avec un titre pareil, que vais-je aborder dans cet article ? Les dernières annonces de la Russie de vouloir se déconnecter du réseau Internet ? Le « great firewall » chinois ? La fin de l’Internet mondial, libre et accessible à tous ? Non, je pense que je vais rester sur un sujet beaucoup plus… léger. J’ai choisi aujourd’hui de parler d’une tendance de plus en plus marquée dans le développement web actuellement : le mode offline-first.
Qu’est-ce que c’est ?
Le mode offline-first c’est tout simplement la possibilité pour une application web de fonctionner sans accès internet. Pour cela, on va s’appuyer sur un cache pour y placer les ressources essentielles au fonctionnement de notre application. De ce côté-là, pas de mystère il faudra toujours avoir, à un moment ou à un autre, pu récupérer ces données grâce au réseau. J’avoue donc avoir menti : le titre de l’article aurait dû être « Vers un Web sans avoir accès à Internet mais en ayant quand même un peu accès pour pouvoir récupérer les ressources indispensables pour que mon application fonctionne » mais c’était beaucoup trop long…
Pourquoi ?
Après tout c’est vrai, pourquoi vouloir une webapp sans web ? Une webapp n’est-elle pas, par définition, une application en ligne ?
Cette innovation présente en réalité 3 principaux avantages :
- Tout d’abord le fonctionnement en mode offline. L’expérience proposée à l’utilisateur est certes dégradée par rapport à la version online mais l’application reste parfaitement utilisable.
- La rapidité de chargement. Pas valable sur la première visite (il faut bien récupérer les ressources une première fois) mais, sur toutes les visites suivantes, les fichiers HTML, CSS, JavaScript seront chargés depuis le cache, évitant ainsi le temps de transfert réseau. On obtient donc une webapp qui s’ouvre instantanément, à la manière d’une application mobile.
- La réduction de la charge réseau. Directement lié au point précédent, pas de requêtes puisque les fichiers sont servis depuis le cache.
Cette pratique trouve un écho tout particulier dans les marchés émergents où la connexion se révèle parfois être une « fainéante lunatique ».
Comment faire ?
Cette volonté d’offrir une meilleure expérience utilisateur n’est pas nouvelle et a déjà été le théâtre de plusieurs essais, plus ou moins fructueux. Petit tour d’horizon :
L’ancêtre : Application Cache
Le fonctionnement d’Application Cache ou AppCache est très simple.
- On liste dans un fichier manifest les ressources que l’on souhaite mettre en cache.
Un fichier manifest est un simple fichier texte portant l’extension.appcacheet dont la structure est normalisée.
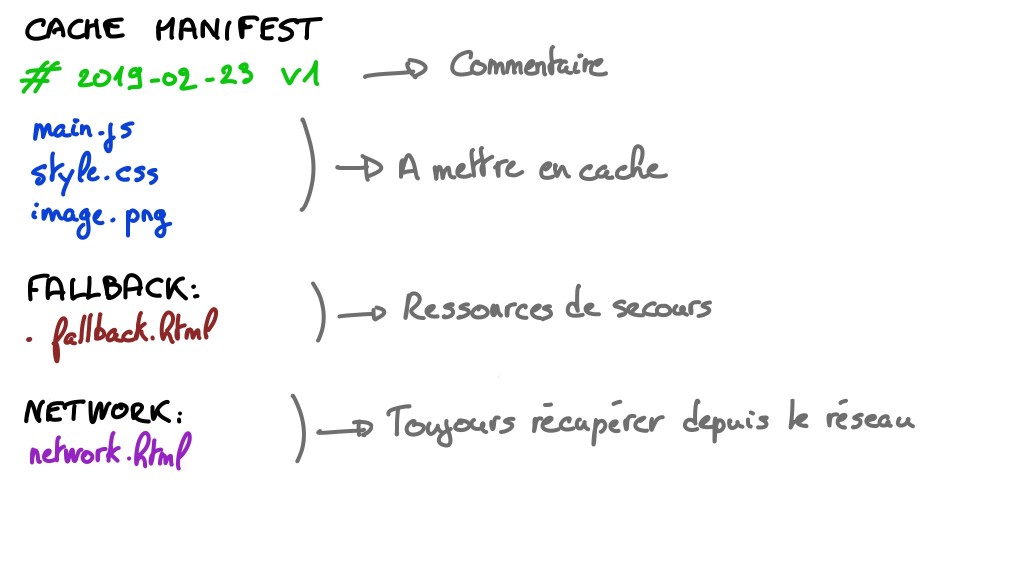
A noter que le commentaire n’est pas là simplement pour décorer. Si un seul bit du fichier manifest a changé, AppCache va re-télécharger toutes les ressources qu’il contient. Modifier le commentaire est donc un moyen simple (quoiqu’un peu bancal) de demander la mise à jour de l’AppCache. - On ajoute un attribut manifest à la balise html sur chacune des pages de notre application.
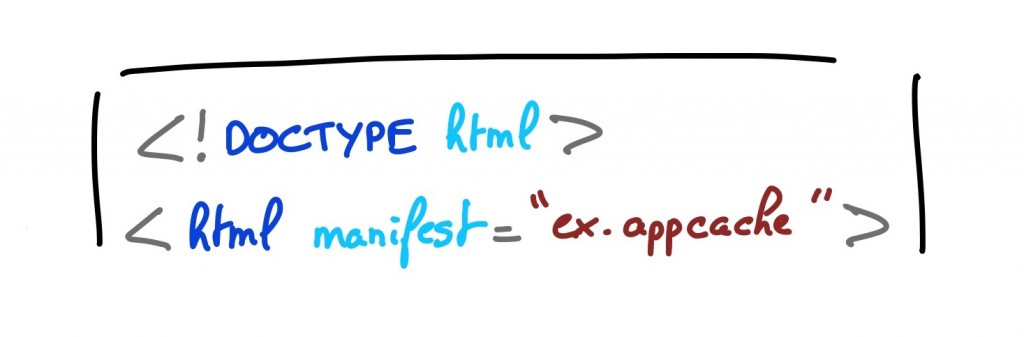
Nul besoin par contre d’ajouter la page html « mère » au manifest. Toute page possédant un attribut manifest est automatiquement ajoutée à l’AppCache - … Et c’est tout. Quand je vous disais que c’était simple…

En pratique, AppCache utilise un cache spécifique (l’AppCache justement) qui n’est pas accessible pour le développeur. Le seul point d’entrée est le fichier manifest, la suite est gérée automatiquement. Et voici comment ça fonctionne :
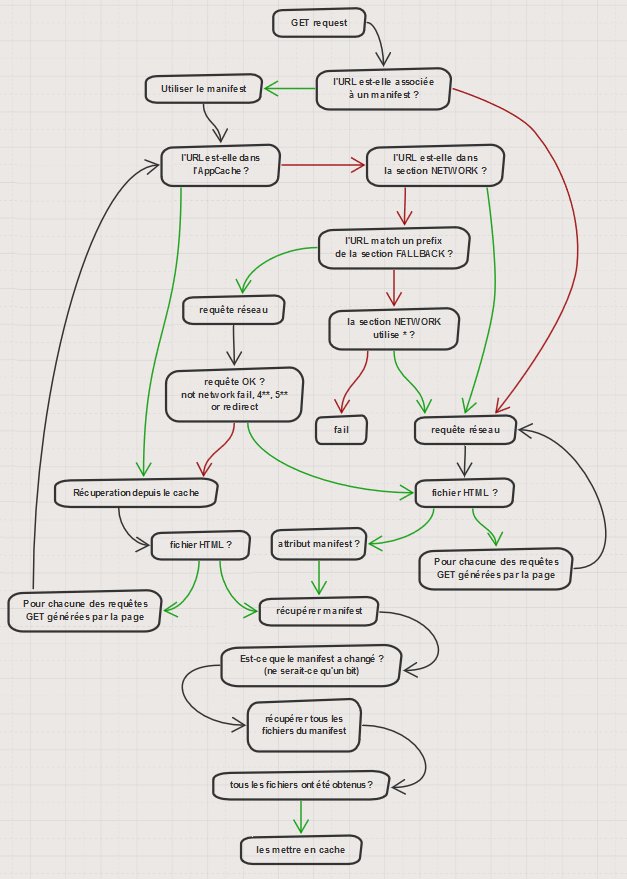

Vous n’y comprenez rien ? vous avez justement compris l’essentiel : Application Cache est beaucoup trop compliqué pour l’utilisation. On prétend que la dernière personne à avoir essayer de comprendre ce diagramme s’est finalement tourné vers des énigmes plus abordables comme la construction des pyramides par les extraterrestres.
En outre AppCache comporte un nombre important de « gotcha ». Je ne résiste pas à l’envie d’en mentionner un en particulier que je trouve assez fun.
Vous vous souvenez de ce commentaire dans le manifest qu’on modifie pour signifier à l’AppCache de se mettre à jour ? Un peu tordu comme mécanisme vous ne trouvez pas ? Ainsi, en bon développeur que vous êtes, vous vous dites : « pourquoi ne pas versionner le nom du fichier manifest plutôt ? Ça me parait beaucoup plus propre. Allez va pour manifest-v1.appcache! ». Et c’est ainsi que notre histoire commence…
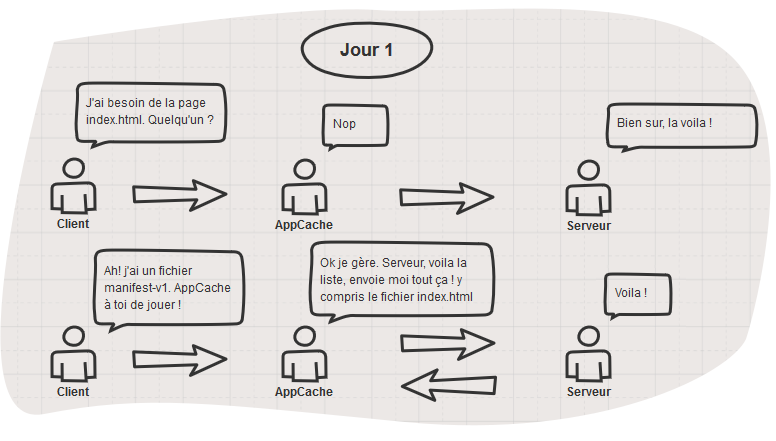
Tout semble se passer pour le mieux n’est-ce pas ? Et pourtant un drame se trame… Vous ne voyez pas ? Poursuivons…
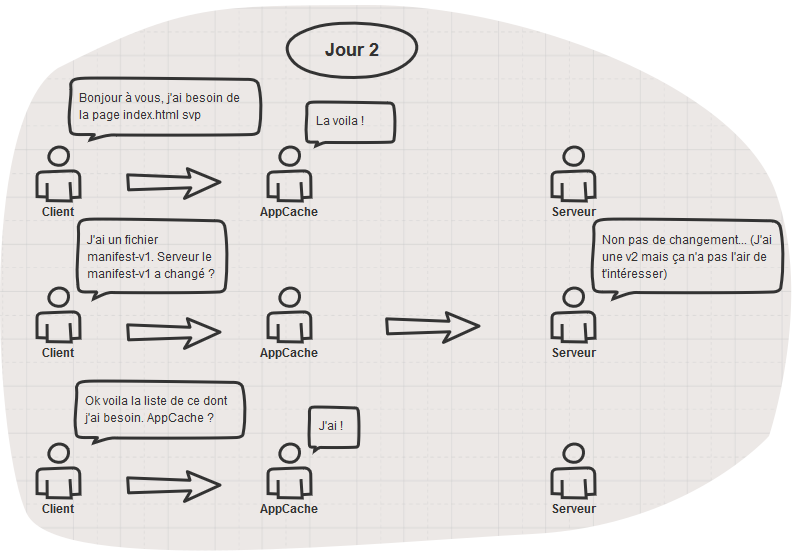
Tiens ?! la page index.html est servie par l’AppCache ? Est-ce que ça ne va pas poser problème ça ? ![]()
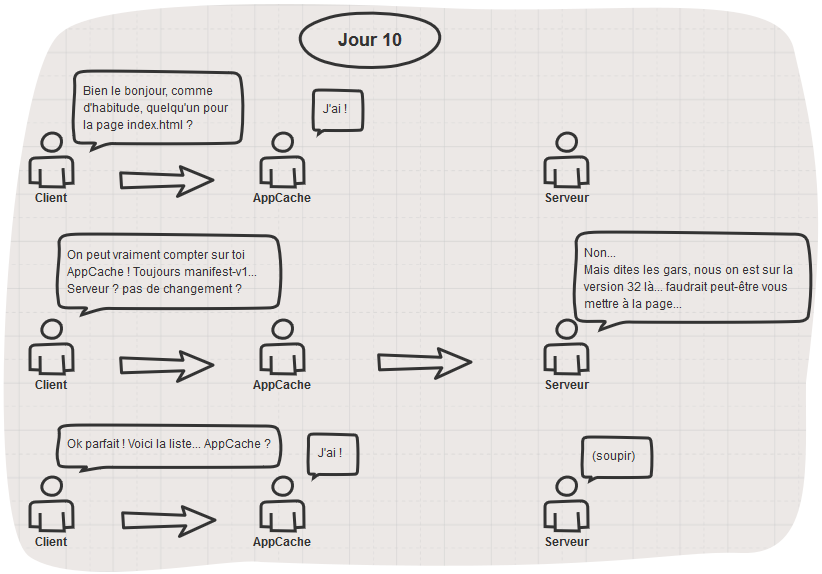
Heu…
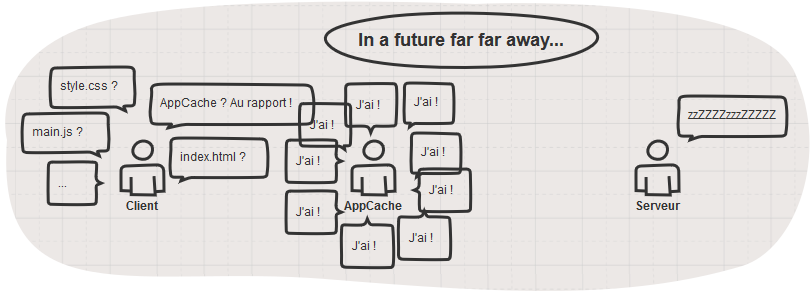
Vous avez compris maintenant ?
Comment AppCache sait s’il doit mettre ses fichiers à jour ? Allez vous connaissez la réponse, il suffit de lire le schéma au dessus… ![]()
Bon OK je vous aide. C’est en vérifiant auprès du serveur si le manifest a changé ou non.
Mais d’où vient le fichier manifest ? Facile, il est donné par l’attribut dans la balise html de la page index.html
Et la page index.html vient de ? l’AppCache ! Ah m…
Eh oui, la page index.html venant de l’AppCache, elle comportera toujours la référence vers le manifest-v1 qui lui ne changera jamais puisque vous avez justement décider de versionner le fichier. Nous voici piégé à jamais dans une boucle temporelle, condamné pour l’éternité à errer encore et toujours sur cette même version du site ! Le scénariste du film « Un jour sans fin » aurait-il été développeur web ?
En résumé, ne faites JAMAIS ça.
Si vous souhaitez aller plus loin, je vous conseille cet article qui liste de manière exhaustive ces « gotchas ». Même sans lire, vous pouvez voir à la taille de l’article qu’il y en a quelques-uns.
Pas de panique cependant, j’ai gardé le meilleur pour la fin, AppCache est déprécié ! Nul besoin donc de vous arracher les cheveux pour comprendre tout ça, vous pouvez (et devez) passer directement à la suite. A moins bien sûr que vous n’ayez à supporter IE… (mais soyons honnête, un développeur qui assure le support IE a déjà fini de s’arracher les cheveux depuis longtemps).
Pour finir, je vais quand même nuancer un peu mon propos. Jusque-là, j’ai été assez critique mais il faut reconnaitre qu’AppCache est extrêmement utile et a, pendant longtemps, été le seul à remplir le rôle qui est le sien. Aujourd’hui en revanche, il souffre de la comparaison avec les nouvelles solutions beaucoup plus puissantes dont disposent les développeurs et on peut s’aventurer sans trop de risques à dire qu’il va progressivement disparaitre.
Le Jeune Loup: Service Worker
Si vous êtes dans le développement web, peu de chances que vous n’en ayez jamais entendu parler. C’est la brique de base des PWA (Progressive Web App). Les services workers (notés simplement SW dans la suite de cet article) peuvent parfaitement assurer le rôle remplit par AppCache, et bien plus encore.
Qu’est-ce que c’est ?
Un service worker c’est simplement un worker (donc un fichier JavaScript qui va s’exécuter dans un thread à part) un peu particulier qui se « place » entre la page et le réseau et qui va agir comme un proxy. Cependant, à la différence d’un worker, il n’est pas lié au contexte d’une page html et va continuer de « vivre » même si la page est fermée. Ce SW va ainsi pouvoir « écouter » toutes les requêtes effectuées par le navigateur et éventuellement se substituer au réseau pour servir un fichier en cache, à la manière du cache http.
Comme AppCache, le SW va utiliser un cache spécifique parmi les différents caches disponibles pour un navigateur.
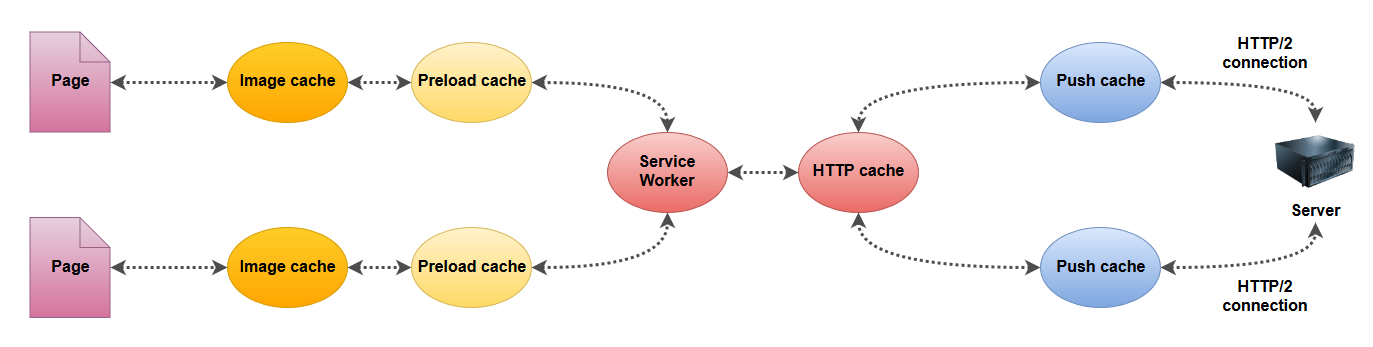
A noter par rapport au schéma ci-dessus, le cache SW est situé « avant » le cache http. Ainsi, même si on demande au SW de récupérer une ressource sur le réseau, elle sera servie depuis le cache http si elle s’y trouve. Il convient donc d’adapter nos « caching headers » http pour fonctionner avec notre SW.
Définir une stratégie
A la différence d’AppCache qui ne nous offre aucun contrôle sur le cache, celui utilisé par les SW est complètement personnalisable grâce à l’API Cache.
Libre au développeur de définir différentes stratégies de cache en fonction des ressources qu’il cherche à récupérer.
- Cache First : on tente de récupérer les fichiers depuis le cache et, s’ils ne sont pas disponibles, on se rabat sur le réseau.
- Cache Only : Le nom est assez explicite, on récupère les fichiers depuis le cache, point.
- Network First : idem que cache first mais inversé.
- Network Only : comme son nom l’indique ou « pourquoi s’embêter à créer un SW dans ce cas là ?! » mais c’est possible.
- StaleWhileRevalidate : certainement la stratégie la plus utile, on sert les ressources depuis le cache, et en parallèle, on met à jour ces ressources depuis le réseau. Cela permet d’avoir des ressources disponibles très rapidement, tout en récupérant les données les plus récentes.
Ces différentes stratégies apportent un contrôle et une granularité au niveau du cache qui font cruellement défaut à AppCache. Pour résumer, un SW fait tout ce que peut faire AppCache, en mieux. Il n’y a donc aucune raison de ne pas migrer vers les SW, à moins bien sur qu’ils ne soient pas disponibles dans le navigateur (qui a dit IE ?).
Mais ce n’est pas tout
Avec les SW sont introduit plusieurs nouveaux évènements dans le navigateur, évènements auxquels on peut bien sur affecter des « listeners », ouvrant ainsi la porte à de nouvelles fonctionnalités :
- Le background sync
Au lieu d’envoyer simplement mes données vers le serveur comme dans le cas de la soumission d’un formulaire, je vais les enregistrer dans ma base IndexedDB (rendez-vous dans la partie suivante si vous ne voyez pas ce que c’est). Puis, je vais utiliser un de ces événements spécifique aux SW :syncqui est déclenché à chaque fois que je récupère la connexion réseau (ou quand elle est déjà présente bien évidemment). A ce moment-là, je vais récupérer mes données en base et les envoyer au serveur. Cela permet de continuer à utiliser son application même en mode offline, et pas seulement pour la récupération de ressources/données mais aussi pour l’envoi.
A noter que cette fonctionnalité n’est pour l’instant disponible que sous Chrome et Opéra mais elle est en cours de développement sous Firefox et Edge. - Le periodic sync
Cette fonctionnalité n’est pour l’instant prise en charge par aucun navigateur mais je la mentionne car elle est en développement sous Chrome (et quand un navigateur représentant 60% des utilisateurs dit quelque chose, les autres écoutent). Je ne serais donc pas surpris de la voir débarquer prochainement dans les spécifications des SW.
Grâce au periodic sync, je vais pouvoir demander à mon SW de se mettre à jour à intervalles de temps régulier par rapport aux données de mon serveur. Et surtout cela se fait dans un thread à part, ne perturbant pas l’expérience utilisateur. - Les web push notifications
Certainement LA fonctionnalité qui manquait le plus par rapport aux applications natives, la possibilité de recevoir des notifications. Pour expliquer très brièvement le principe, chaque éditeur de navigateur implémente son propre service de push. Mon application, elle, va lui demander d’envoyer tel message à tel utilisateur et c’est ce push service qui va se charger d’envoyer un événement de typepushau navigateur de l’utilisateur. Le SW va capter cet évènement et faire apparaitre une notification.
Mais là vous vous dites : « comment le push service sait à quel client il doit envoyer l’évènement ? ». Très bonne question, c’est en fait au moment où l’utilisateur accepte de recevoir des notifications de la webapp qu’on va générer une souscription et l’enregistrer auprès du push service.
Ceci est une présentation très succincte de la fonctionnalité. L’ensemble des flux est beaucoup plus complexe mais cela suffit, je pense, à se rendre compte de l’intérêt des web push notification.
C’est grâce à ce genre de nouveautés que les PWA parviennent à proposer sur une webapp une expérience utilisateur identique à une application native. J’utilise moi-même la PWA de Twitter sur mon smartphone et je dois dire qu’elle fonctionne même mieux que l’application mobile !
Si avec tout ça je n’ai pas réussi à vous convaincre de tester les SW, alors je ne peux plus rien faire. Mais il me reste quand même encore un petit point à aborder…
Données dynamiques
Vous l’avez peut-être remarqué, mais jusqu’ici je ne parle que de données statiques, des fichiers HTML, CSS et JS, des images, … tout ce qui constitue ce qu’on appelle l’app-shell. Mais qu’en est-il du contenu dynamique de mon application ?
C’est bien de pouvoir ouvrir mon application en mode offline mais s’il n’y a rien dedans, quel intérêt ?
Pour continuer sur l’exemple de Twitter, si on s’arrête à la mise en cache de l’app-shell on pourra ouvrir l’application mais aucun post ne sera affiché. On se retrouvera pour ainsi dire avec une coquille vide. Je ne sais pas pour vous mais personnellement j’en attends un peu plus d’une application web sensée fonctionner en offline.
IndexedDB à la rescousse
Si je vous en parle, c’est bien évidemment qu’il est possible d’enregistrer ces données dynamiques pour pouvoir les afficher si l’on est en mode offline. On peut même décider d’afficher directement ces données au démarrage de l’application, le temps de récupérer le contenu le plus récent du serveur (c’est le principe de la stratégie « StaleWhileRevalidate » des SW). Ainsi mon application Twitter aura toujours des posts affichés, même si ceux-ci ne sont pas les plus récents qui soient.
Pour cela on va utiliser les différentes solutions de sauvegarde de données dynamiques :
- IndexedDB
C’est LA base de données à utiliser. Les données sont stockées sous formes d’objets JavaScript soit des ensembles de paires clé-valeur, un peu à la manière NoSQL. Elle est disponible sur tous les navigateurs. Oui, vous avez bien lu TOUS, même IE (quoiqu’un peu buggé) pour une fois. Toutes les interactions avec IndexedDB sont asynchrones et utilisent, on ne sait pourquoi, leur propre implémentation des promesses (j’imagine qu’un éditeur de navigateur devant un standard se sent comme un vampire face à une gousse d’ail…). Heureusement, il est possible d’utiliser des surcouches comme idb qui permettent d’interagir avec IndexedDB sur la base de vraies promesses cette fois. - WebSQL
C’est une API de stockage basé sur SQL. Elle est dépréciée depuis novembre 2010 (ah quand même !). Elle a pendant longtemps été la seule option sur Safari et elle est encore aujourd’hui supportée par Chrome et Safari. Toutefois, Safari supportant maintenant IndexedDB, il n’y a plus aucune raison de l’utiliser, à moins que vous n’ayez à assurer le support de vieux navigateurs. - WebStorage
C’est une API là encore qui permet de stocker des paires clés-valeurs un peu à la manière des cookies mais plus simplement, sans rien ajouter aux headers http, et en proposant un volume de stockage beaucoup plus important (5MB contre 4Ko). Très pratique pour passer des données d’une page à une autre sans faire intervenir le serveur, il ne faut cependant pas oublier que ces données sont stockées sur le disque et donc y accéder de manière raisonnée. De plus, les données étant enregistrées coté client, elles ne sont pas accessibles coté serveur (contrairement aux cookies).
Bien entendu, il serait fastidieux d’implémenter nous-mêmes, à chaque fois, les « features detection » pour savoir quelles solutions sont disponibles dans le navigateur actuel, et les éventuelles solutions de repli. Heureusement, de nombreuses libraries comme PouchDB (directement inspirée d’Apache CouchDB), dexie ou encore localForage de Mozilla prennent tout ça en charge pour nous.
Pour conclure
Le but affiché de ces webapps en mode offline-first est de proposer une meilleure expérience utilisateur, en prenant en compte les marchés émergent où le débit moyen de connexion est beaucoup plus faible. Pour cela, l’utilisation massive des nouvelles fonctionnalités apportées par les services workers, qui sont en train de devenir des briques incontournables du développement web, est essentielle. Attention toutefois, comme à chaque fois, plus de libertés implique plus de responsabilités. Si les caches et base de données sont à disposition du développeur, il lui appartient également de mettre en place une politique de nettoyage, sans quoi le navigateur s’en occupera lui-même et il n’est pas du genre à faire dans le détail.
-
Alex Mustiere
-
Stéphane Liétard