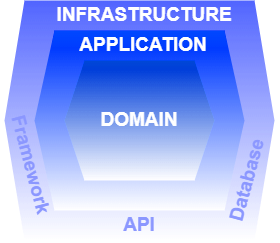
Architecture en couches vs architecture Hexagonale
Introduction
Dernièrement, j’ai assisté à un évènement OxLive (événement technique mensuelle organisé chez Oxiane) sur un retour d’expérience d’un développeur Oxiane en mission chez un client. Son expérience m’intéressait beaucoup car le sujet concernait l’implémentation d’une architecture hexagonale dans son projet back-end. L’architecture hexagonale n’est pas un sujet nouveau puisqu’elle est définie pour la première fois par Alistair Cockburn en 2005. Robert C. Martin a repris plus récemment en 2012 les concepts en définissant la clean architecture. Néanmoins, de par mon expérience, ces concepts ont du mal à s’appliquer dans nos DSI, puisque dans la plupart des cas, un tout nouveau projet démarre sur une architecture classique en couches.
J’étais donc très enthousiaste à l’idée de découvrir d’une part, ce type d’architecture et d’autre part, de connaître les raisons et arguments qui ont permis de mettre en place ce type d’architecture.
Des schémas pour commencer …
Pour introduire son discours, l’animateur a ainsi tout naturellement commencé par présenter les différences entre une architecture hexagonale et avec une architecture dite “classique” en couches.
Voici le schéma présenté pour démontrer ces différences :
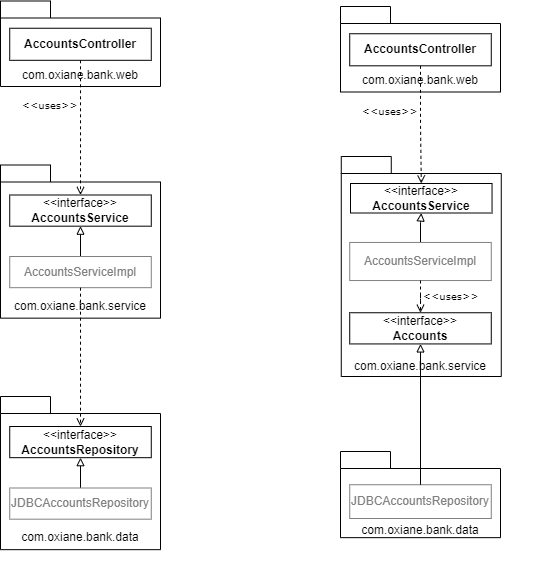
De premier abord les différences ne m’ont pas sauté aux yeux. Et pour vous ?
Les deux schémas présentent les interactions entre trois packages d’une application Java.
Les schémas proposent une structuration de l’application en package, mais un découpage en module Maven ne change en rien sur les principes évoqués dans le reste de ce billet de blog. Chaque package symbolise une couche de l’application. Pour les deux schémas, on retrouve ainsi de haut en bas les packages suivants :
- com.oxiane.bank.web : la couche présentation contenant un contrôleur Web
- com.oxiane.bank.service : la couche de traitement (ou couche métier) définissant la logique métier.
- com.oxiane.bank.data : la couche d’accès aux données également appelée couche de persistance. L’implémentation de l’interface Repository utilise l’API JDBC pour accéder à une base de données (SGBD)
Le schéma de gauche présente les packages d’une architecture en couches que nous connaissons tous. Le schéma de droite présente les packages dans une architecture hexagonale.
J’étais donc un peu déçu car il n’y a à priori rien d’extraordinaire ni de révolutionnaire.
La différence majeure et ses conséquences
La “seule” différence entre les deux schémas est le positionnement de l’interface “AccountsRepository/Accounts”. En effet, dans un modèle en couches, cette interface est présente dans la couche d’accès aux données (data) alors qu’elle est présente dans la couche métier dans une architecture hexagonale. Cette simple différence est minime mais elle change tout !
La conséquence majeure concerne le changement des dépendances entre les packages. Dans le schéma de gauche, en regardant le sens des flèches en pointillées, les dépendances vont de haut en bas : le web utilise et dépend donc du métier, et le métier dépend de la couche data. Dans le schéma de droite, c’est différent, toutes les dépendances vont vers la couche métier (flèches en pointillées également). En schématisant on retrouve alors l’hexagone dont l’intérieur représente le Domaine et qui va donc contenir tout le code métier de votre application :

Qu’est-ce qui fait que ce changement apporte des avantages indéniables ?
1- Un code métier épuré
Dans une architecture en couches classique, puisque la couche métier dépend de la couche d’accès aux données, il est alors techniquement possible et très “tentant” d’utiliser des objets de la couche data dans la couche métier, et ceci même en utilisant des modules Maven en lieu et place de package Java. Même avec une extrême rigueur (ou non !), le code métier se retrouve alors très rapidement noyé avec du code technique comme par exemple du code de framework tiers. Dans combien de projet a-t-on vu l’utilisation d’objets annotés Hibernate ou JPA dans le code de la couche métier ? Pire, très souvent ces objets remontent même jusqu’à la couche de présentation (web).
Pourquoi est-ce mal me direz-vous ? Trois raisons principales à cela :
- la première est que le code métier est moins lisible car pollué par des éléments techniques
- la seconde est que le code métier est moins testable car il nécessite alors l’utilisation du code de la couche dépendante. Le code métier devient donc fragile face aux changements.
- la troisième raison est qu’il est plus difficile mais pas impossible, de changer de framework technique sans entraîner de potentielle régression fonctionnelle dans le métier. Le code métier est donc moins pérenne car plus fragile aux évolutions et/ou changements des frameworks techniques.
A contrario, la couche métier dans l’architecture hexagonale ne dépend de rien : le code métier est alors agnostique de l’infrastructure. L’objectif est de conserver l’intérieur de l’hexagone en dehors de tout code technique. Ainsi la couche métier ne fait aucun appel au réseau, ni à aucun middleware et n’a aucune adhérence à framework technique (ORM, Spring etc..), excepté si besoin à des frameworks de type extension du langage comme Guava en Java par exemple.
Quels en sont les avantages ?
- Le code est plus lisible : une personne du métier doit pouvoir lire et comprendre du code de la couche métier (si le code est bien écrit bien évidemment). La conséquence à cela est un code moins buggé car écrit en collaboration avec le métier et pas seulement par le développeur. D’ailleurs il est à noter que l’interface AccountsRepository a été renommée Accounts, qui a plus de sens d’un point de vue métier ; Repository étant un terme technique.
- Le code est testable plus facilement car les tests ne nécessitent pas l’introduction de framework, ni de démarrer des serveurs de base de données ou autres.
- La montée de version ou le changement de framework technique n’a aucun impact sur le code de l’hexagone.
2- La couche métier est l’élément central
Dans le schéma de gauche, rien n’empêche au package web, via son contrôleur, de réaliser un appel direct au code de la couche d’accès aux données sans passer par le code de la couche métier.
Ce type direct de dépendance entre le web et les données n’est en général pas conseillé sauf cas particulier. Pourquoi ? Parce qu’au fil du temps, le développeur va, par manque de rigueur ou par manque de temps, injecter du code de la logique métier dans la couche web ou dans la couche d’accès aux données. C’est catastrophique car on retrouve alors du code métier dans toutes les couches de l’application !
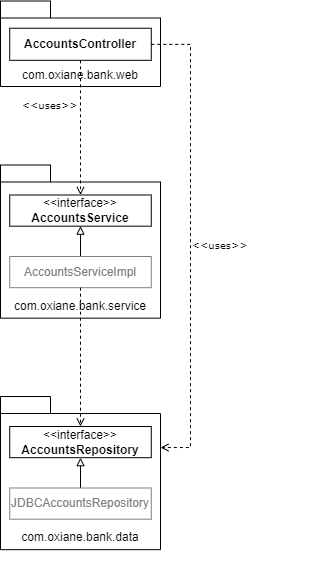
Dans une architecture hexagonale, l’appel direct du web au code d’accès aux données n’est pas impossible mais cet appel viole un principe de conception. En effet, le contrôleur, pour réaliser l’appel, doit posséder une référence à une implémentation (JdbcAccountsRepository) et non à une interface (qui est, rappelons-le, présente dans l’hexagone). Cela est contraire au principe d’inversion des dépendances (lettre D du principe SOLID) qui stipule que les entités doivent dépendre des abstractions, pas des implémentations. Tout appel de ce genre doit donc faire bondir tout bon développeur et donc signaler qu’il y a un problème.
3- Commencer par ce qui a de la valeur : le métier
Le dernier avantage et changement majeur est pour moi celui qui a le plus d’importance, c’est à dire le plus d’impact sur le développement d’une application.
Le problème avec l’architecture en couches est que les développeurs vont avoir tendance à commencer le développement de la couche d’accès aux données. Pourquoi ? Parce qu’il s’agit de la couche qui ne dépend d’aucune autre couche. Il est donc “tout naturel” de commencer par cette couche. Les développeurs vont tout naturellement calquer la base de données sur le modèle de données. En soit, cela n’est pas incohérent, mais lorsque le développeur va réaliser le code de la couche métier, quel sera alors son intérêt de re-définir des classes métiers alors qu’elles existent déjà dans la couche persistance puisque ces dernières sont calquées sur le modèle. On se retrouve alors avec des objets anémiques (des structures de données en fait) contenant des annotations Hibernate dans le code métier. Pour éviter ce problème, le développeur va alors introduire des méthodes métier. Ah !!! On a introduit du code métier dans la couche de persistance !
Avec l’architecture hexagonale, ce danger ne peut pas survenir. On commence par le code métier, et le développeur n’a pas à se soucier de savoir comment ces données seront persistées, ni d’ailleurs comment elles seront utilisées par la couche de présentation.
Commencer par la couche métier offre plusieurs avantages :
- Le démarrage d’un projet est plus rapide puisqu’il n’est pas nécessaire de mettre en place toute l’infrastructure qui va graviter autour. Un corollaire à cela est que l’on peut livrer plus rapidement des fonctionnalités métier.
- L’équipe de développement est focalisée en premier lieu sur le métier. La valeur ajoutée d’une application n’est pas dans l’utilisation du dernier framework à la mode, ni dans le fait d’utiliser une base NoSQL, mais bel et bien dans l’objectif de répondre à une problématique métier. Le reste, c’est-à-dire l’infrastructure, n’est que du détail.
- Retarde les choix technologiques. Très souvent, au démarrage d’un projet il est extrêmement difficile de connaître quelle solution technique est la plus adaptée à votre projet. Après l’implémentation de la logique métier, les connaissances métier de l’équipe sont meilleures et permettent à ce moment-là de faire les meilleurs choix en ce qui concerne l’infrastructure. Par exemple, on peut se rendre compte qu’utiliser une base SQL est surdimensionnée par rapport au besoin, et qu’une simple utilisation de fichiers comme mode de stockage est amplement suffisant (anecdote racontée par Oncle Bob sur FitNess).
Conclusion
Dans ce billet de blog, je n’ai pas cherché à expliquer dans le détail ce qu’est l’architecture hexagonale (même s’il n’y a rien de compliqué au final) car beaucoup de littérature existe sur le sujet. Je suis simplement parti du constat qu’il n’existe pas de grandes différences d’un point de vue technique entre une architecture en couches et une architecture hexagonale. La philosophie de l’architecture hexagonale est que le métier est l’élément principal et central d’une application et doit être complètement exempt de toutes technologies. Cela apporte de nombreux avantages comme nous l’avons vu, même s’il existe quelques inconvénients non mentionnés dans cet article.
Pourquoi alors l’architecture hexagonale a-t-elle du mal à s’imposer, même si c’est de moins en moins vrai ? Une des raisons est, selon moi, que la plupart des développeurs aiment la technique (j’en fais partie !) au détriment du fonctionnel et de ce fait cherchent dès le départ à chercher des solutions techniques. Mais au final l’un n’empêche pas l’autre, donc adoptez l’architecture hexagonale dans vos projets !