ServiceLoader et annotations
Lors d’une formation Java 9-11 que j’animais cette semaine, on m’a demandé un exemple d’usage de ServiceLoader, de modules, et de filtrage des implémentations par annotation.
Lors d’une formation Java 9-11 que j’animais cette semaine, on m’a demandé un exemple d’usage de ServiceLoader, de modules, et de filtrage des implémentations par annotation.

Après avoir détaillé les différentes JEPs de Java 18 dans la première partie de cet article, cette seconde partie est consacrée aux autres améliorations notamment
Java 18 a été publié le 22 mars 2022.
OpenJDK 18 est l’implémentation de référence de la version 18 de la plateforme Java, telle que spécifiée

On ne présente plus Github comme gestionnaire de code source… mais, depuis 2018 il s’affirme également comme outil complet d’intégration continue !
En 2018, dans le sillage
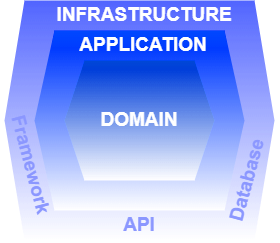
Introduction
Dernièrement, j’ai assisté à un évènement OxLive (événement technique mensuelle organisé chez Oxiane) sur un retour d’expérience d’un développeur Oxiane en mission chez un client.
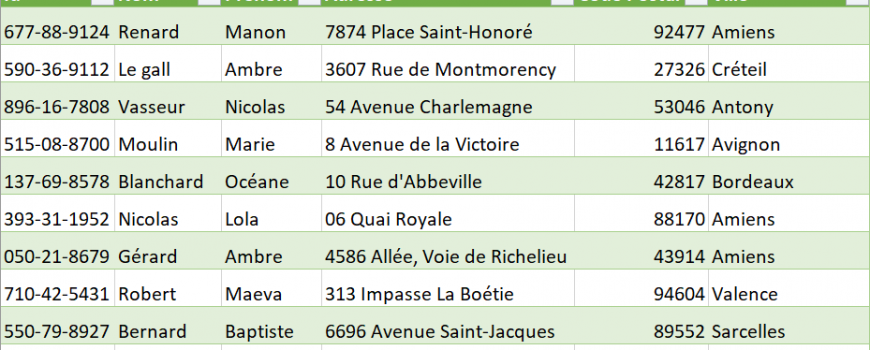
Il est fréquent d’avoir besoin de générer des données factices (fake data), notamment pour les tests automatisés : pour des mocks ou des données d’une

Au travers de l’utilisation d’un plugin, Visual Studio Code facilite le développement dans WSL en permettant de créer et modifier des fichiers sous Linux mais
Ce quatrième article s’intéresse à l’utilisation de Docker dans WSL-2.
Comme vu dans le premier article, Windows Subsystem for Linux (WSL) 2 propose un changement architectural
L’article précédent a détaillé l’installation de WSL 2 et d’une distribution Linux. Cet article détaille l’utilisation de WSL 2.
Démarrer une distribution
Plusieurs possibilités sont proposées pour

Je vais vous faire part d’un retour d’expérience que j’ai eu dans un projet informatique chez un client leader européen : l’organisation de travail en « Mob